
Motivation
Reporting sucks. It feels kind of silly how easy it has become to access the very bleeding edge in some technologies—building and training neural networks with millions of parameters, setting up intricate data processing pipelines, getting creative with visualization libraries—only to have it all culminate in a shitty powerpoint™ presentation or a bland pdf document. And then when someone asks for an update 2 months later…🤯🔫.
“What about Jupyter notebooks?“ you must be wondering… they’re a great tool to showcase an analysis piece—think kaggle kernels—but I think they’re closer to replacing a standalone project rather than something that you would send to clients or your boss with some frequency.
Another good alternative is Plotly’s Dash:
Written on top of Flask, Plotly.js, and React.js, Dash is ideal for building data visualization apps with highly custom user interfaces in pure Python. It’s particularly suited for anyone who works with data in Python.
I’d say Dash is a great tool if you need more advanced visualizations, but it’s definitely an order of magnitude more involved because besides all of the additional coding required, you need to figure out hosting. Heroku is a great option in terms of simplicity, but it doesn’t come cheap.
This tutorial will show you how to set up a data pipeline to ingest and clean some data, and then present it with nice, interactive dashboards that can be freely shared and exported to pdf. Once you’re done, you’ll have online reports with interactive visualizations and filtering, that will be a breeze to update and share with you’re end users.
The pipeline
Our first task is setting up a data processing pipeline, which will run periodically to ingest the data and clean it up. Maybe it’s in a SQL database, or it gets dumped in some folder or S3 bucket as CSV files, maybe you have some code scraping a website, maybe you hook up to an API… this step is obviously going to be completely project dependent, but the general workflow is always the same; read the data into pandas dataframes, process it (add/remove columns, fill missing values, merge and denormalize, etc.), and then export to google sheets. This is an ooold workflow traditionally referred to as Extract Transform Load.
Getting data
On this occasion, we’ll be using the NYPD motor collisions data. It gets updated daily, and each record represents a collision with information like precinct, borough, involved vehicles, etc.
We’ll write a python script that gets and cleans the data. This is where you’ll denormalize it if you’re reading from multiple tables (in case you’re reading from a SQL database), add new columns, clean them up, etc. I like doing this step in Jupyter notebooks first, which allows me to interact directly with the data and see what needs to be done. Once I’m more familiar with the data and happy with the transformations required, I’ll put them all together into a script like this one.
1# data_processing.py2import pandas as pd34def get_data():5 """ Gets data. Returns a pandas df """6 base_url = 'https://data.cityofnewyork.us/resource/qiz3-axqb.json'7 df = pd.read_json(base_url)8 return df910def clean_data(df):11 """ Cleans data. Returns a pandas df """1213 # Make a copy so the function remains pure14 df = df.copy()1516 # Let's drop some columns that we won't use17 drop_cols = [col for col in df.columns if col.startswith(':')]18 drop_cols.append('location')19 df.drop(drop_cols, axis=1, inplace=True)2021 # Looks like the street names need to be stripped22 street_cols = [23 'cross_street_name',24 'off_street_name',25 'on_street_name',26 ]27 for col in street_cols:28 df[col] = df[col].str.strip()2930 # Create lat,long col31 df['coordinates'] = df['latitude'].astype(str) +32 ', ' +33 df['longitude'].astype(str)3435 return df3637def etl():38 """ Main function. Gets and cleans data. Returns a pandas df """39 df = get_data()40 df = clean_data(df)41 return df
There’s nothing very fancy going on in this file, and what you do with the data depends on what you have so there’s no point in covering it here. What does deserve some attention is how you structure the process. Here I split the work into 2 different functions, one to load the data and another one to transform it. Then I put both together into a third function that I’ll call later for the full process.
The benefit of splitting it into separate functions is that it makes it much easier to test, debug and maintain. If your cleaning process is more complex than what I have here (and most likely it is) it may make sense to split things further into individual functions for each step. If you’re coming from a Jupyter notebook where you did the initial exploration, it will probably be a very direct conversion from each code bock into its own function.
Exporting to Google sheets
Next, we need to export the data to google sheets. To do all the heavy lifting we’ll use the great library gspread, which is very well documented and easy to start using right out of the gate. But we’ll only be using a small portion, that will allow us to dump the data into a pre-determined sheet.
First thing is getting credentials from the google developers console. This section of the gspread docs covers it but I’ve found it to be a bit outdated—or at least partially incomplete—so I’ll cover it here as well. UI’s are constantly changing so I won’t rely to heavily on it, most steps are relatively easy to figure out.
- Go to the google developers console and create a new project—call it whatever you want.
- You’ll be taken to the project dashboard. Right there in the middle you should see a link that says “+ ENABLE APIS AND SERVICES”. Go there, search for “Google Drive API” and click on enable. Then go back and search for “Google Sheets API” and enable as well. Go back to the main project dashboard.
- To the left, you’ll see a menu that has 3 items as of this writing: Dashboard, Library and Credentials. Go to credentials, and create a new service account key.
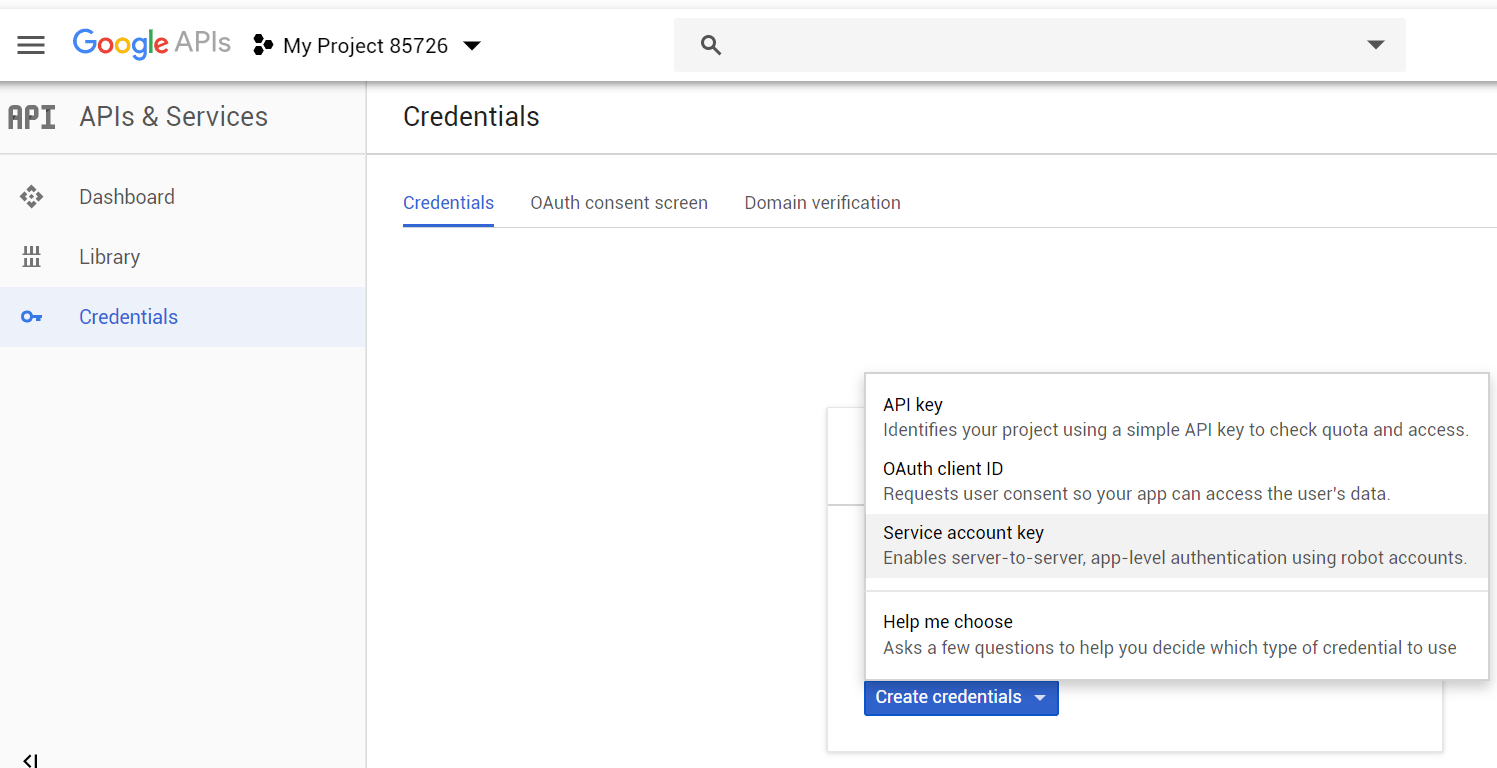
- Give the service account a name, and give it the “Editor” role (note that the ‘sodium-task-xxx’ name was randomly generated by google).
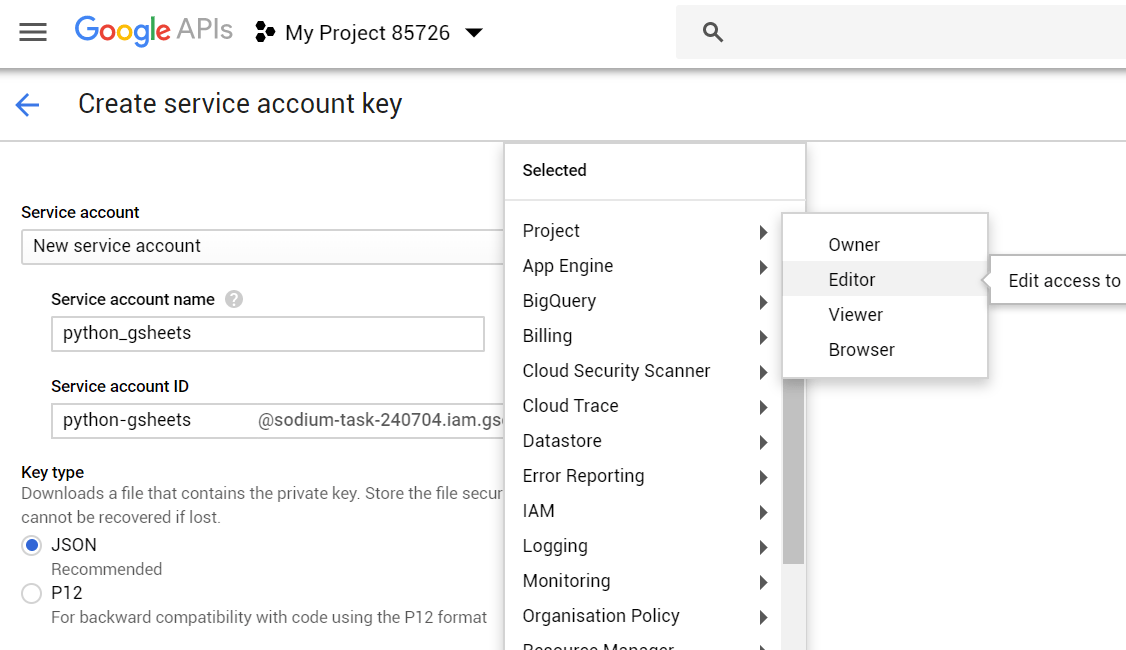
- Save the output to your project directory as
google_secrets.json - Now you must create the google sheet, and share it with the email created for that service account (in my case
python-gsheets@sodium-task-240704.iam.gserviceaccount.com). You can also find that email address inside the json file you just downloaded. You’ll realize you forgot this step if you later get aSpreadsheetNotFounderror when running the code.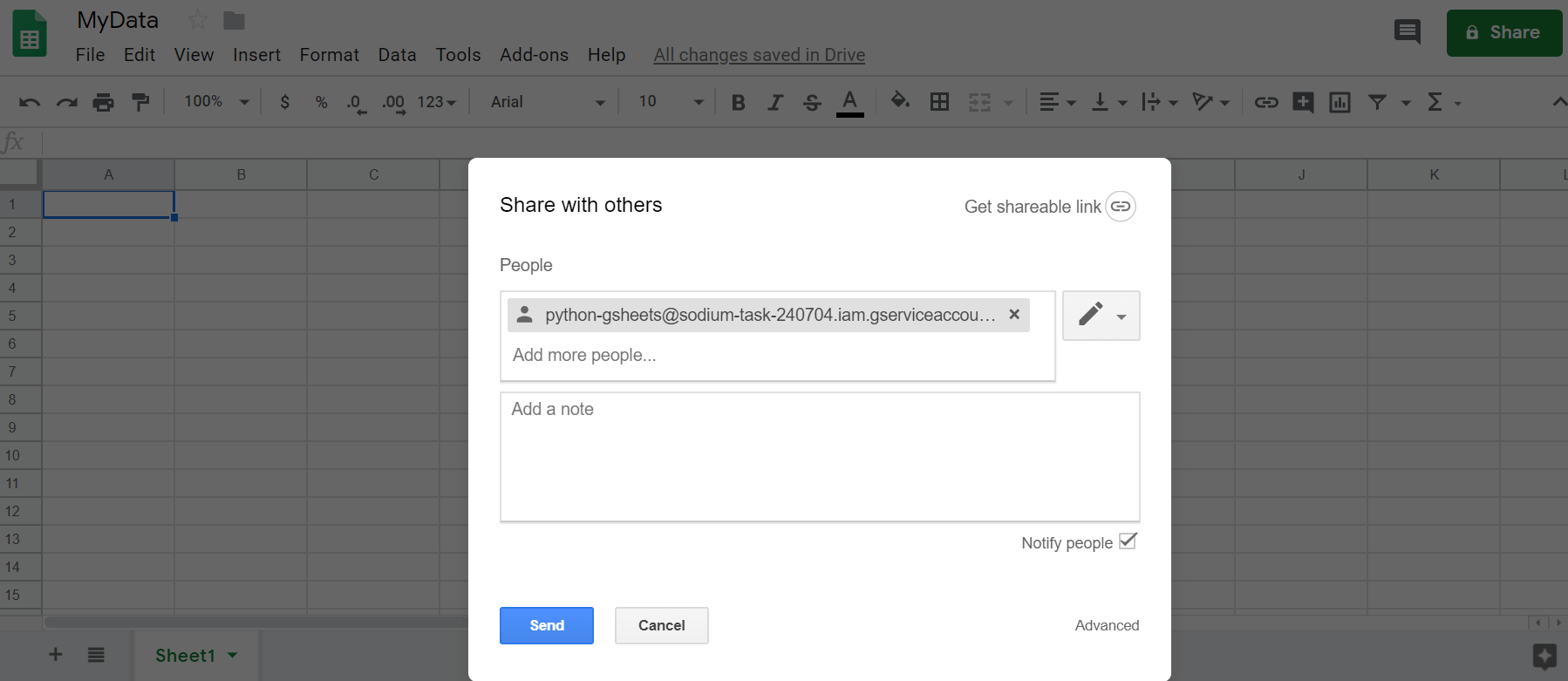



Once that’s done, we’ll define some functions that will help us create, open and write to sheets. Put these functions in a file that we’ll call from the main one. The main function we’ll call here, paste_csv, will go to a given tab within a given spreadsheet, delete all contents and paste a given CSV string. You can adjust this code to append the data to the bottom instead of overwriting—if you want to preserve the data—although I would suggest against it.
If the goal was collecting historic data instead of (or in addition to) just reporting on the current status, I would edit the process to append the pandas dataframe to the bottom of a CSV file and then write another piece of code that reads the data from this file and dumps whatever you need into the google sheet—basically separating the tasks of building a historic database and reporting on it. I prefer this approach because google sheets isn’t really made to handle millions of rows, so even if you start small your dataset will eventually grow enough that you’ll have to make the switch anyways—why not do it from the start.
1# gspread_utils.py2import gspread3from oauth2client.service_account import ServiceAccountCredentials456def get_client(creds_file='google_secrets.json'):7 """8 use creds to create a client to interact9 with the Google Drive API10 :param creds_file: 'clients_json11 :return: gspread Client object12 """13 scope = ['https://spreadsheets.google.com/feeds' +14 ' ' +15 'https://www.googleapis.com/auth/drive']16 creds = ServiceAccountCredentials.from_json_keyfile_name(creds_file,17 scope)18 client = gspread.authorize(creds)19 return client202122def get_last_row(tab):23 """ Helper function to find last row with data """24 last = tab.row_count25 if last < 1:26 return 127 return last282930def get_last_col(tab):31 """ Helper function to find last col with data """32 last = tab.col_count33 if last < 1:34 return 135 return last363738def clear_contents(tab):39 """ Delete all data in a given tab40 (must be a gspread sheet object) """41 last_row = get_last_row(tab)42 last_col = get_last_col(tab)43 range_of_cells = tab.range(1, 1, last_row, last_col)44 # This section is not very performant (to put it mildly) but it45 # still only takes a few seconds for thousands of rows. While the46 # goal of this script is to run offline, this is not a big issue.47 for cell in range_of_cells:48 cell.value = ''49 tab.update_cells(range_of_cells)505152def paste_csv(csv_data, sheet,53 tab_name='Sheet1',54 starting_cell='A1'):55 '''56 Deletes content in sheet (if exists) and pastes csv data57 csv_data - csv string58 sheet - a gspread.Spreadsheet object59 cell - string giving starting cell60 '''61 # If the tab doesn't exist, create it62 try:63 tab = sheet.worksheet(tab_name)64 except:65 tab = sheet.add_worksheet(title=tab_name,66 rows="20", cols="5")67 clear_contents(tab)6869 (first_row, first_column) = gspread.utils.a1_to_rowcol(starting_cell)7071 body = {72 'requests': [{73 'pasteData': {74 "coordinate": {75 "sheetId": tab.id,76 "rowIndex": first_row-1,77 "columnIndex": first_column-1,78 },79 "data": csv_data,80 "type": 'PASTE_NORMAL',81 "delimiter": ',',82 }83 }]84 }85 sheet.batch_update(body)
Now let’s put both pieces of code together into a third file.
1# etl_gsheets.py2import gspread_utils3import data_processing45def main():6 """ gets clean data and dumps into google sheets """78 # Get data9 df = data_processing.etl()1011 # Send to Google sheets12 client = gspread_utils.get_client(creds_file='google_secrets.json')13 # MyData is the name of the google sheet14 sheet = client.open('MyData')15 gspread_utils.paste_csv(df.to_csv(index=False),16 sheet,17 tab_name='Sheet1',18 starting_cell='A1')1920if __name__ == '__main__':21 print('Starting..')22 main()23 print('All done!')
Now for the moment of truth, go to the shell and run the code:
1$ python etl_gsheets.py
If all goes well, you should go to your google sheet and see the data there. Hooray! Now whenever you run this command, the entire pipeline will kick in, getting the data, cleaning it up and dumping it in the Google Sheet you gave it.
Data Studio Dashboard
Now we’ll create a data studio report and populate it with the data we just created. The tool is a very simple, yet powerful visualization tool that allows easy report creation and sharing. I’d say the sharing portion is the standout feature: you can share it freely and aren’t restricted like with paid products (Power BI, Tableau, etc.). Another feature I like a lot is how easy it is to embed them, as they make an html snippet readily available to copy and paste wherever you want (scroll to the bottom to see mine). While you have a much more limited spectrum of available visualizations (no fancy force graphs here) I find it’s offering is almost always more than enough—remember the goal here is replacing an excel chart anyway.
I won’t cover it’s usage too much here—you just have to play around with it. Unfortunately, you’ll find that most users come from google analytics and therefore most of the data handling is already taken care of for them because you can connect directly to it—and other data sources too, which is actually pretty neat. However, this means it’s harder to find help online—the [google-data-studio] StackOverflow tag has just 555 questions as of this writing.
Creating the report
- Go to https://datastudio.google.com and create a new report.
- Click on “Create new data source” or something like that. It will probably be to the right.
- Scroll down until you find “Google Sheets”. Click there, and look for your newly created spreadsheet, and then click on “Connect”.
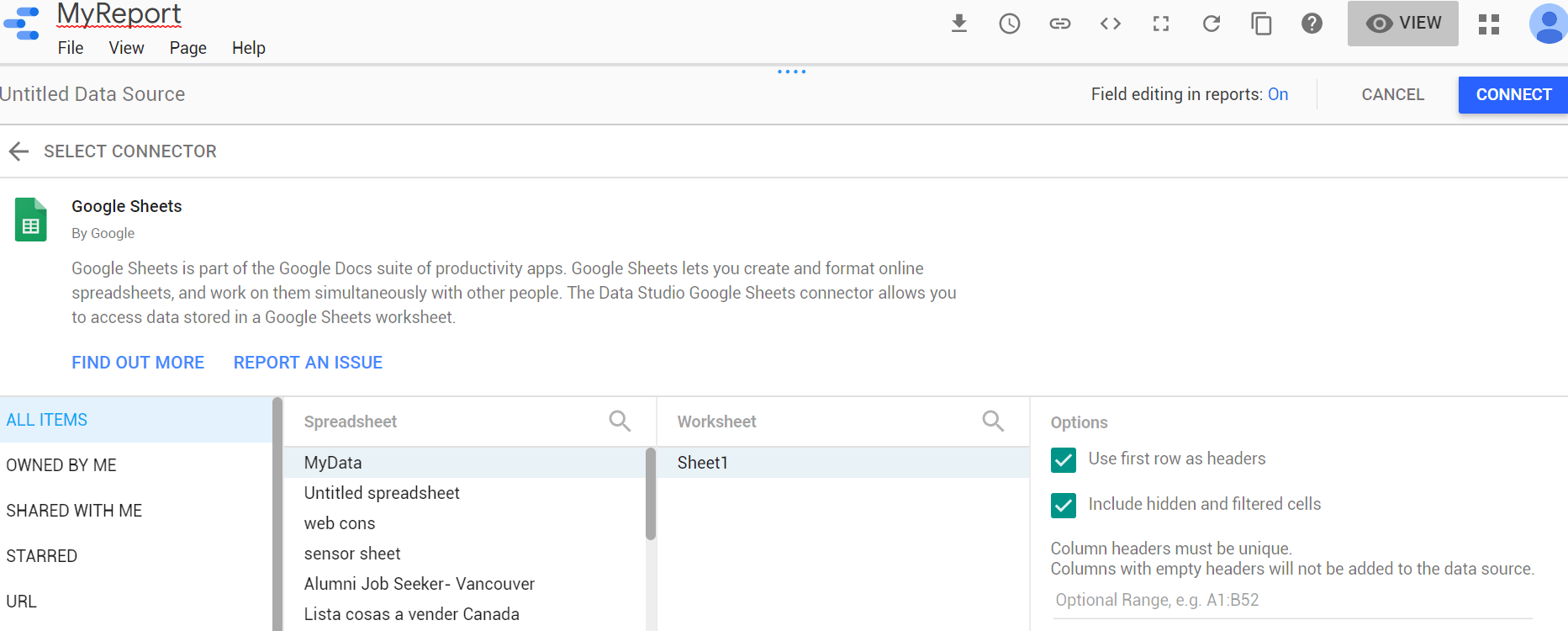
- You’ll see all your columns there, colorized the way data studio breaks down your data: greens are dimensions and blues, metrics. In very simple terms, dimensions are columns that represent categories through which you can slice your data (country, date, sector, etc.) and metrics are the values that you want to visualize (income, temperature, etc.). You can adjust the data types if any was read incorrectly, and define formatting and aggregation preferences (average for percentages, sum for money, etc.). You can also create new fields, but I found this to be much easier to do in the python data processing layer. This also applies to blended data, which is a data studio feature that allows merging data sets like classic SQL JOINS, but again, I prefer doing all of these within python and just dumping the data ready to visualize.
- Once in the main panel, you can switch between the EDIT and VIEW modes to edit your report. I won’t cover all the features here, but encourage you to just play around with it—it is mostly pretty intuitive and if you can’t figure out how to do a specific thing (apply filter to a subset of charts, add default to dropdown list, etc.) you’ll probably find the answer in google. While the data connection side has small online support because most people use it for google analytics, the report building and visualizations community is much more active because of this as well.
- Each object (chart, filter, text box) has a DATA and a STYLE tab in the control bar to the right, where you can determine what the object will display and formatting. Depending on the visualization, you can choose one or more dimensions, which are the green-colored columns that correspond to categorical variables, and metrics, the blue-colored ones that represent values. You can also select a “Date Range Dimension” that allows you to use the “Date Range” filter, in addition to regular filters.

Finished product
As mentioned earlier, reports are very easy to share and publish. You can set rules to define who can view or edit it, and get an html snippet to embed into websites as you can see below. Note the “Full Screen” symbol on the bottom-right corner (so you don’t have to squint).
Next steps
Now you’re done with the basic version. Want to kick it up a notch and go fully automated? move this code over to an AWS Lambda function and set it to run on a fixed schedule or whenever your data updates.

